P2257 YY的GCD
1 |
|
[POI2007]ZAP-Queries
1 |
|
P3327 [SDOI2015]约数个数和
1 |
|
P2522 [HAOI2011]Problem b
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
直接上python
1 | a=int(input()) |
把每个数sqrt时间分解因子,然后枚举因子个数
1 |
|
直接递推
1 |
|
只要知道gcd(fn,fm)=F(gcd(n,m))然后用一下矩阵快速幂就行
1 |
|
1 |
|
1 |
|
只要把对角线的规律找出来就OK
1 |
|
找出第一个字符然后八个方向直线过去就行
1 |
|
1 |
|
把周围的0都涂完剩下的就是答案
1 |
|
格子太大查询太多直接暴力会超时,所以采用联通快加速
1 |
|
1 |
|
线性基的题型相对比较固定,看到下面的类型基本上都是线性基了:
线性基中的题目中还用到一个技巧:
这便是线性基的全部东西了。
1 | struct Linear_Basis{ |
1 |
|
按顺序参加舞会,参加一个舞会要穿一种衣服,可以在参加完一个舞会后套上另一个衣服再去参加舞会,也可以在参加一个舞会的时候把外面的衣服脱了,脱到合适的衣服,但是脱掉的衣服不能再穿,参加完全部舞会最少穿多少次衣服
区间dp,dp【i】【j】表示区间i->j之间的衣服数 起始情况i->i要穿一件衣服
可以从后往前推
特别的如果第i 和第j个衣服是一样的
然后开始在区间{I,J}之间选择K;
如果K的衣服和I的衣服一样代表 到K的时候可以把衣服脱到剩I的时候 这样就是K前面的衣服加上K->J的衣服
1 |
|
给出一个的只有’(‘,’)’,’[‘,’]’四种括号组成的字符串,求最多有多少个括号满足题目里所描述的完全匹配。
用dp[i][j]表示区间[i,j]里最大完全匹配数。
只要得到了dp[i][j],那么就可以得到dp【i-1][j+1]
dp【i-1]【j+1]=dp 【i]【j]+(s[i-1]与[j+1]匹配 ? 2 : 0)
然后利用状态转移方程更新一下区间最优解即可。
1 |
|
给你一个只有括号的字符串,
1,每个括号只有三种选择:涂红色,涂蓝色,不涂色。
2,每对括号有且仅有其中一个被涂色。
3,相邻的括号不能涂相同的颜色,但是相邻的括号可以同时不涂色。
因为是一个合法的括号序列。
所以每个括号与之匹配的位置是一定的。
那么就可以将这个序列分成两个区间。 (L - match[L] ) (match[L]+1, R)
用递归先处理小区间,再转移大区间。
因为条件的限制,所以记录区间的同时,还要记录区间端点的颜色。
然后就是一个递归的过程。
1 |
|
给出N个数,每次从中抽出一个数(第一和最后一个不能抽),每次的得分为抽出的数与相邻两个数的乘积,直到只剩下首尾两个数为止,问最小得分是多少
枚举起点和终点 ,但是这次长度要从3开始了因为中间必要取一个
1 |
|
记忆化搜索
1 |
|
有一个队列,每个人有一个愤怒值D,如果他是第K个上场,不开心指数就为(K-1)*D。但是边上有一个小黑屋(其实就是个堆栈),可以一定程度上调整上场程序
对于区间 [x, y] 中的数字 a[x],有可能第1个出栈,也有可能最后一个出栈,如果第k个出栈的话前i+1->k个数字要按照顺序出栈,然后a[x]出栈,[k+1,y]出栈。对于a[x]要加上a[x]×(k-i)的花费,对于[x+1, y]要加上sum(x+1, y) * (i-x+1)的额外花费。
1 |
|
给出两个长度相同的字符串a, b.对a可以进行区间更新(选择一个区间,把这个区间全部更新成相同的字符),问要最少操作a多少次,a才能等于b?
先处理一下b串 用DP存b串i到j的改变次数 然后再对a串进行状态转移。对于串b,最要是看两个相同字符之间的区间了。我们可以预处理出来改变区间[x, y]里面的字符,操作的最小次数用dp[x, y]来存储。
预处理完了以后,我们就可以用dp来匹配a了。ans[i] 表示 a字符区间[0, i] 与 b字符区间[0, i]相同的最小操作数目。状态转移就是:ans[i] = min (dp[0, i], ans[j] + dp【j+1】i], ans【i-1)
1 |
|
就是输出序列a[n],每连续输出的费用是连续输出的数字和的平方加上常数M
让我们求这个费用的最小值。
概率DP的入门题,把我搞得要死要活的。
首先dp[i]表示输出前i个的最小费用 很简单得得出一个方程
其中sum[i]表示数字的前i项和,但是这个方程的复杂度是n^2 所以这时候就要用到斜率优化 ,ps:个人感觉斜率DP都用到了队列,来把前面绝对不优秀的项都出队,这样每次运算都只要在队列中找就行,而且每个元素只有一次出队和入队 所以复杂度只有N
首先假设在算dp[i]的 ,k<j<i,并且J点比K点优秀
那么
对上面方程分解整理得:
注意正负号,不然会影响不等号的方向
另
于是上面的式子变成斜率表达式
由于不等式右边的sum[i]随着i的增加而递增
所以我们另
1.如果上面的不等式成立 说明J比K优,而且随着i的增加上述不等式一定是成立的,也就是对于以后的i来说J都比K优秀,所以K是可以淘汰的
2.如果
那么J是可以淘汰的
假设g[I,J]<sum[i] 就是I比J优秀,那么J就没存在的价值
相反,如果g[I,J]>sum[i] 那么同样有g[J,K]>sum[I] 那么K比J优秀 所以J是可以淘汰的
所以这样相当于维护一个下凸的图形,斜率在增加,用队列维护
ps:以上都是抄bin巨的博客
1 |
|
水题,主要是拿来试试模板
F[i]=f[i-1]-f[i-2]
1 |
|
1 |
|
给出矩阵的第0行(0,233,2333,23333,…)和第0列a1,a2,…an(n<=10,m<=10^9),给出式子:
假设要求A[a]【b]则

相当于上图,红色部分为绿色部分之和,而顶上的绿色部分很好求 左边的部分就是前一列的(1-n)的和
所以我们只要知道第一列和第一行就能推出任意列@
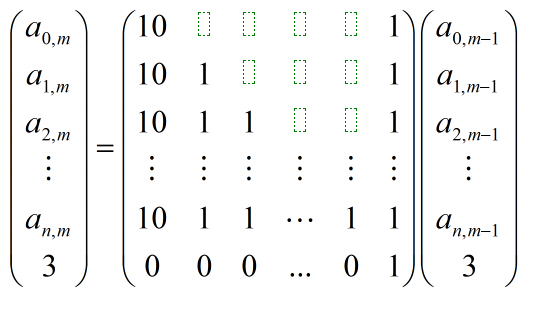
构造上图的中间矩阵,因为第0列到第一列不符合 所以手动求出第一列的答案,然后再求出中间矩阵的m-1次方 和第一列相乘就是答案了
1 |
|
题目给我们一个O(N)求值程序 让我们求这个值在操作N次后的答案
n&1->ans=ans*2+1;
else->ans=ans*2;
因为数据量很大(1e9)所以很可能会超时,所以只能用加速算法
现在我们考虑只有偶数项
如果是偶数就直接求n/2次方,如果是奇数就求出二次方后再*2+1;
1 |
|
题意很简单,给你一个N×K的矩阵A,再给你一个K×N的矩阵B N<=1000,K<=6
1.求出矩阵C=A×B
2.求出矩阵C^n*n
3.求出矩阵C的和
一开始直接模拟,于是很愉快的超时了,发现如果是A×B 是N×N的矩阵1000×1000
于是一个骚操作出现了A×B的N的平方的平方 可以才成A×B×A×B×A…×B 于是可以变成A×(B×A)^(n×n-1)×B 这里B×A是6×6的矩阵速度快的一批;长见识了!
1 |
|
水题不解释了
1 | int t; |
计算矩阵A^1+A^2+A^3+…A^k

1 |
|
给出a+b的值和ab的值,求a^n+b^n的值
令a+b=A,ab=B,S(n)=a^n+b^n。则S(n)=a^n+b^n=(a+b)(a^n-1+b^n-1)-abn-1-an-1b=(a+b)(a^n-1+b^n-1)-ab(a^n-2+b^n-2)=A×S(n-1)-B×S(n-2) (n≥2)。
1 |
|
a,b,n,m都是整数,Sn向上取整 并且(a-1)^2<b<a^2

1 |
|
中文题
直接做做不来的,列举几个情况
1 | 0 a |
很容易看出a和b的项数各自符合斐波那契数列 然后可以用矩阵求出各自的项数,再用快速幂求出结果
注意因为这里的项数太大 所以要使用费马小定理/欧拉降幂
1 |
|
An Arc of Dream is a curve defined by following function: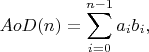
where
a0 = A0
ai = ai-1×AX+AY
b0 = B0
bi = bi-1×BX+BY
What is the value of AoD(N) modulo 1,000,000,007?
题意太好理解了就不解释了

1 |
|
1 | struct DA{ |
有N(1<=N<=20000)个音符的序列来表示一首乐曲,每个音符都是1..88范围内的整数,现在要找一个重复的子串,它需要满足如下条件:1.长度至少为5个音符。
2.在乐曲中重复出现(就是出现过至少两次)。(可能经过转调,“转调”的意思是主题序列中每个音符都被加上或减去了同一个整数值)
3.重复出现的同一主题不能有公共部分。
对于第一二点:至少长度是五,我们可以二分0-n/2之间的长度来查找height(height[i]=排名为i和i-1的后缀子串的最长公共前缀长度缀)然后找到两个大于二分的值,然后判断起点距离是否大于二分的值(因为要求不重叠)</br>
第三点 因为共同加上一个值,但是他们前后的差值还是一样的(例如1,2,3和5,6,7是一样的他们的差值是1)然后把原数组变成一个长度为N-1的数组去处理,因为处理后的数组比原数组少1所以答案也要-1;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91//#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll mod=998244353;
const int maxn=2e5;
const ll inf=0x3f3f3f3f3f3f;
int sa[maxn];
//sa[i]名次为i的后缀的起始位置;
//Rank[i]起始位置为i的名次 ->Rank[sa[i]]=i;
//height[i]名次为i和i-1的后缀的最长公共前缀长;
int t1[maxn],t2[maxn],c[maxn];
int Rank[maxn],height[maxn];
bool cmp(int *r,int a,int b,int l){
return r[a]==r[b]&&r[a+l]==r[b+l];
}
int s[maxn];
void da(int str[],int n,int m){
int i,j,p,*x=t1,*y=t2;
for(i=0;i<m;i++)c[i]=0;
for(i=0;i<n;i++)c[x[i]=str[i]]++;//***
for(i=1;i<m;i++)c[i]+=c[i-1];
for(i=n-1;i>=0;i--)sa[--c[x[i]]]=i;
for(j=1;j<=n;j<<=1){
p=0;
for(i=n-j;i<n;i++)y[p++]=i;
for(i=0;i<n;i++)if(sa[i]>=j)y[p++]=sa[i]-j;
for(i=0;i<m;i++)c[i]=0;
for(i=0;i<n;i++)c[x[y[i]]]++;
for(i=1;i<m;i++)c[i]+=c[i-1];
for(i=n-1;i>=0;i--)sa[--c[x[y[i]]]]=y[i];
swap(x,y);
p=1;x[sa[0]]=0;
for(i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
if(p>=n)break;
m=p;
}
int k=0;
n--;
for(i=0;i<=n;i++)Rank[sa[i]]=i;
for(i=0;i<n;i++){
if(k)k--;
j=sa[Rank[i]-1];
while(s[i+k]==s[j+k])k++;
height[Rank[i]]=k;
}
}
bool isok(int n,int k){
int ma=sa[1],mi=sa[1];
for(int i=2;i<=n;i++){
if(height[i]<k)ma=mi=sa[i];
else{
if(sa[i]<mi)mi=sa[i];
if(sa[i]>ma)ma=sa[i];
if(ma-mi>k)return true;
}
}return false;
}
int main()
{
std::ios::sync_with_stdio(false);
std::cin.tie(0);
std::cout.tie(0);
int n;
while(cin>>n&&n){
for(int i=0;i<n;i++)cin>>s[i];
for(int i=n-1;i>0;i--)s[i]=s[i]-s[i-1]+90;//因为四十行要用s[i]的值做下表所以不能出现负数
n--;//变化后的长度-1
for(int i=0;i<n;i++)s[i]=s[i+1];
s[n]=0;
da(s,n+1,200);
int ans=-1;
int l=1,r=n/2;
while(l<=r){
int mid=(l+r)/2;
if(isok(n,mid)){
ans=mid;
l=mid+1;
}
else r=mid-1;
}
if(ans<4)cout<<0<<endl;
else cout<<ans+1<<endl;
}
return 0;
}
最长可重叠重复K次子串问题。
二分答案
1 |
|
最长不可重叠重复子串问题
只要判断长度是否大于二分的就行
1 |
|
经典的最长公共子串问题//
如果同一段旋律在作品A和作品B中同时出现过,这段旋律就是A和B共同的部分,比如在abab 在 bababab 和 cabacababc 中都出现过。小Hi想知道两部作品的共同旋律最长是多少?
把两个字符串接在一起就变成了求后缀的最长公共前缀的问题,但是由于这个前缀不能跨越两个字符串,所以我们在第一个字符串后面加上一个没有出现过的字符,再接第二个字符串,然后取所有非同一个串后缀的height的最大值…
1 |
|
重复次数最多的连续字串
小Hi平时的一大兴趣爱好就是演奏钢琴。我们知道一个音乐旋律被表示为长度为 N 的数构成的数列。小Hi在练习过很多曲子以后发现很多作品中的旋律有重复的部分。
我们把一段旋律称为(k,l)-重复的,如果它满足由一个长度为l的字符串重复了k次组成。 如旋律abaabaabaaba是(4,3)重复的,因为它由aba重复4次组成。
小Hi想知道一部作品中k最大的(k,l)-重复旋律。
求重复次数最多的连续字串
假如知道了这个连续子串的开始位置
并且知道了它的长度
那么,此时我们就通过lcp(i,i+len)来进行比较即可
但是,如果枚举长度和开始的位置的话
尽管lcp通过st表可以O(1)查询
但是这个枚举的复杂度是O(n2)的
很显然,需要更快
所以,枚举了长度lenlen之后
我们只需要考虑开始位置为lenlen倍数的地方
如果此时有一个重复串的开始位置不在lenlen的倍数上
很显然的
lcp就会多出一截
所以,我们可以倒推出这个位置
所以,这样枚举复杂度为O(nlogn)
1 |
|
题目即求有多少子串满足ABA的形式,并且满足|A|>0,|B|=G。
搞了我三天三夜的题目
首先可以用后缀数组求出任意两个点的后缀的lcp,然后相同长度减去g就是答案
但是这样复杂度是n^2
然后我们可以发现假设A的长度是L,第一个L在K位置,那么另一个L是K+L+G
然后我们发现如果L和另一个K+L+G判断相同了之后,那么L+1,L+2,…2L-1其实都不用再匹配了
所以我们就直接枚举长度L 然后在0,L,2L,3L进行匹配,注意不仅仅要向后面匹配前缀,还要向前面匹配后缀,后者我们可以把字符串倒置,然后求n-1-k,和n-1-(k+l+g)的lcp 这样两个lcp相加,那A的起点就可以在他们这个范围里面 所以答案就是lcp1+lcp2-L
注意lcp长度不能超过L,因为超过的话就会访问到另一个L的区域了
1 |
|
1 | struct DA{ |
1 |
|
求长度不小于K的公共子串的个数。
对于一个LCP 贡献是len(lcp)-k+1
我们可以将height进行分组,大于等于k的在同一组,如果两个后缀的最长公共子串>=k,那么它们肯定在同一个组内。现在从头开始扫,每遇到A的后缀时,就统计一下它和它前面的B的后缀能组成多少长度>=k的公共子串,然后再反过来处理B的后缀即可,一共需要扫两遍。但是这样的时间复杂度是O(n^2),是行不通的。
因为两个后缀的LCP是它们之间的最小height值,所以可以维护一个自底向上递增的单调栈,如果有height值小于了当前栈顶的height值,那么大于它的那些只能按照当前这个小的值来计算。这样分别处理两次,一次处理A的后缀,一次处理B的后缀。需要记录好栈里的和以及每个组内的后缀数。
注意longlong

1 |
|